The Next Frontier: What Is Audio AGI and How Soundverse Is Building It
(and How Soundverse Is Quietly—or Loudly—Building It)
Contents
- 1. Setting the Stage
- 2. What Exactly Is Audio AGI?
- 3. Different Flavors of Generality: Audio AGI vs. Classic AGI
- 4. A Short History of Machines That Listen
- 5. What New Use-Cases Open Up?
- 6. Can Audio‑First Agents Do Things a “General” AGI Can’t?
- 7. How Soundverse Is Quietly Building Audio AGI
- 8. Ethics and IP
- 9. FAQ: Audio AGI and Soundverse
- 1. What is Audio AGI and how does it differ from other AI music tools?
- 2. How can I try out Soundverse’s Audio AGI features today?
- 3. Are AI‑generated tracks from Soundverse royalty-free?
- 4. How does Soundverse ensure its Audio AGI models are trained ethically?
- 5. Will Audio AGI replace human musicians and composers?
- 10. Looking Forward
- 11. Join the Conversation
1. Setting the Stage
For decades, Artificial General Intelligence (AGI) has been portrayed as an all‑seeing, all‑knowing entity: a machine mind that writes code, debates philosophy, pilots robots, and makes us coffee. Yet most of the public discussion revolves around text and vision—large language models, image diffusion models, multimodal chatbots. Sound has remained the understudied sense, despite the fact that humans rely on it for emotion, memory, and real‑time coordination.
Enter Audio AGI—an intelligence that makes listening, understanding, and creating sound its primary purpose. Rather than trying to master every modality at once, audio‑first AGI aims for super‑human depth on a single channel, using the ear as its gateway to cognition.
If you're asking yourself, "What is Audio AGI and how does it work?"—this is your guide.
2. What Exactly Is Audio AGI?
Simply, Audio AGI is an always‑listening, always‑creating, always‑learning ear‑brain system designed to engage with the world through sound.
An audio‑first AGI should demonstrate four core abilities:
-
Perception at Human (or Super‑Human) Fidelity
It parses pitch, timbre, rhythm, spatial cues, language, and emotion in real time—much like an elite sound engineer with perfect pitch. -
Contextual Understanding
It knows that a lone cough during a symphony matters less than the oboe entrance, or that a Bengali lullaby carries different emotional weight than a Detroit techno drop. -
Generative Creativity
It can compose, remix, or synthesize any sonic artifact a human might imagine—music, Foley, dialogue, and beyond—without rigid templates. -
Adaptive Collaboration
It learns on the fly. New genres, new voices, new production styles become part of its vocabulary without months‑long retraining cycles.
3. Different Flavors of Generality: Audio AGI vs. Classic AGI
The pursuit of AGI takes distinct forms depending on its sensory priorities and operational demands. Below, we contrast Classic AGI (text-vision focused) with Audio AGI (ear-first), highlighting their key differences:
Sensory Priorities
- Classic AGI: Multimodal, with vision and text as dominant inputs.
- Audio AGI: Sound is the primary sense; vision and text play supporting roles rather than leading.
Latency Tolerance
- Classic AGI: Often operates on a timescale of seconds.
- Audio AGI: Demands millisecond-level responsiveness (e.g., live performance, telepresence).
Training Priors
- Classic AGI: Prioritizes world knowledge, language statistics, and image semantics.
- Audio AGI: Focuses on psychoacoustics, music theory, linguistic prosody, and digital signal processing (DSP).
Benchmarking
- Classic AGI: Evaluated via Turing tests, grade-school exams, and image accuracy metrics.
- Audio AGI: Tested through perceptual listening tests, ABX shoot-outs, and live-jam sessions.
Output Modalities
- Classic AGI: Generates text, images, plans, and actions.
- Audio AGI: Produces high-fidelity stereo, spatial stems, MIDI, and real-time effects.
Rather than chasing breadth, Audio AGI prioritizes depth—temporal micro-precision, phase coherence, emotional subtlety, and spatial realism. These requirements challenge the architectural assumptions of traditional AI music creation tools and make Audio AGI the ideal foundation for the next generation of AI sound design.
4. A Short History of Machines That Listen
1960s–1980s: Speech recognition crawls from Morse‑code speeds to dictation accuracy.
1990s: MP3 and DSP chips democratize digital audio processing.
2010s: WaveNet and its offspring prove that neural nets can sound better than concatenative synthesis.
2020s: Diffusion models & latent autoencoders hit record quality, spawning music generators like Soundverse, Suno, and Udio.
Audio AGI is the logical next rung: a single system that fuses speech, music, sound design, and auditory reasoning, ending the era of narrow “one‑model‑per‑task” pipelines.
5. What New Use-Cases Open Up?

Audio AGI isn’t just an upgrade—it’s a revolution. By mastering sound with human-like precision, it unlocks use cases that current technology simply can’t handle:
Real-Time Co-Composition
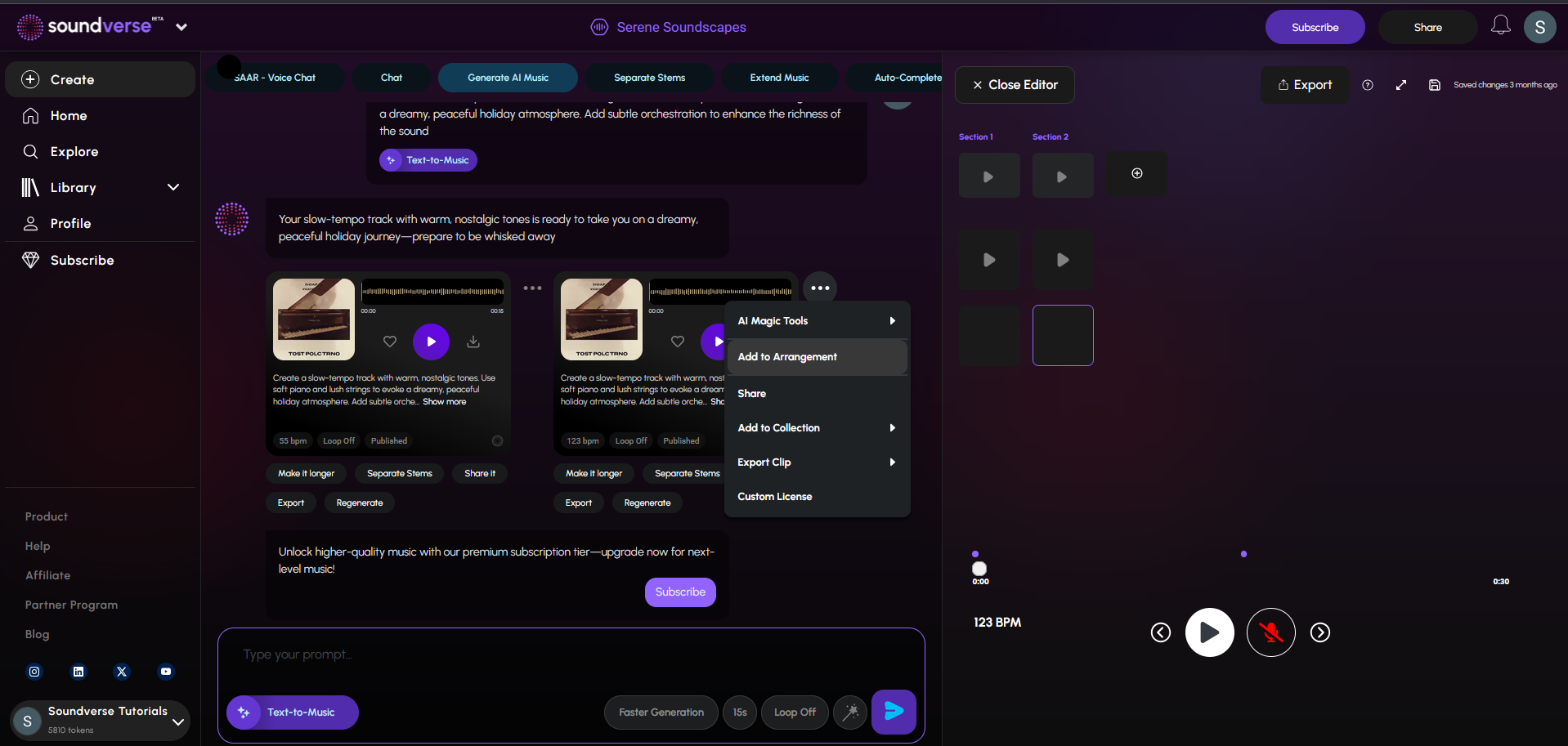
With sub-50ms response times and deep contextual memory, Audio AGI enables frictionless real-time music co-composition with AI—perfect for creators who thrive in live sessions.
Instant Foley & SFX for Filmmakers
Forget bloated sample libraries. Audio AGI generates scene-aware Foley and Atmos stems on the fly, opening a new world of AI-generated Foley and sound effects for filmmakers.
Universal Accent-Preserving Dubbing
By preserving micro-expressions and emotional nuance, Audio AGI makes high-fidelity dubbing possible in any language, solving one of the biggest hurdles in global content distribution.
Adaptive Therapeutic Soundscapes
Real-time sound adjustment based on biometric signals creates deeply personal, adaptive therapeutic soundscapes powered by AI—relevant for wellness apps, VR meditations, and neurofeedback experiences.
Hyper-Personalized Sonic Branding
With the ability to generate custom audio identities, Audio AGI is redefining sonic branding. Marketers can generate on-brand music in minutes using tools like the Soundverse AI Song Generator.
Audio AGI doesn’t just improve existing workflows—it reinvents them, turning yesterday’s pipe dreams into today’s creative toolkit.
6. Can Audio‑First Agents Do Things a “General” AGI Can’t?
Absolutely. In fact, an Audio AGI may outperform generalist AGIs in any task where time, emotion, or sound quality matters most.
-
Latency Sensitivity: LLMs that generate audio often do so with second-level lag. That’s unusable for live jams, podcasting, or streaming. Audio AGI runs at human tempo, generating and reacting to sound in milliseconds.
-
Acoustic Reasoning: Understanding how a voice echoes in a cave vs. a closet? That’s spatial awareness through sound. A text-first AGI can’t hear that difference. An Audio AGI can, and it adapts the audio accordingly—making it ideal for tasks like real-time podcast editing with AI.
-
Collaborative Listening: A musical agent should know when to solo, when to comp, and when to shut up. Audio AGI listens in a way LLMs can’t, enabling collaborative music production with AI tools rather than outputting tracks in isolation.
By mastering sonic nuance, Audio AGI extends the frontier of what AGI can be—from encyclopedic know-it-alls to deeply musical, emotionally responsive partners.
7. How Soundverse Is Quietly Building Audio AGI
Soundverse has a bold but clear mission: to become the world’s leading platform for ethical, AI-powered music and sound creation. While the full technical architecture remains proprietary, the core pillars reveal a system designed for both creativity and responsibility.
Soundverse has spent the last two years quietly (and loudly) building the core architecture for Audio AGI. Here’s how:
SAAR: Conversational Audio Agent

Imagine a chat interface that speaks music instead of just text. With SAAR, a simple prompt like "give this chorus an orchestral lift" translates into rich, dynamic audio adjustments—no technical expertise required. This breakthrough lowers the barrier to professional-grade creativity, empowering even non-musicians to refine their work with precision.
Ethical Data & Attribution Layer
Soundverse trains its models exclusively on licensed, user-submitted, or public-domain audio stems, with embedded metadata to ensure proper provenance. This commitment guarantees that creators and rightsholders are fairly compensated when their work influences new AI-generated content, fostering a sustainable ecosystem.
Our systems only use licensed, permissioned, or artist-submitted data. We’ve implemented opt-outs, style attribution, and real-time explainability into the core model loop. This helps tackle key concerns around copyright and AI music, AI voice cloning ethics, and transparent music attribution.
You can learn more about this and how to join it by visiting our Partner Program page.
A Very Capable Model
Rather than stitching together specialized models for speech, music, and sound effects, Soundverse relies on a single, unified generative engine—optimized for both low latency and high fidelity. This eliminates the brittleness of multi-model pipelines, enabling seamless, real-time creative workflows.
Continuous Self-Improvement Loop
The system evolves through opt-in user feedback and telemetry, fine-tuning its outputs to better match artistic intent while avoiding creative stagnation. Every interaction sharpens its genre awareness and stylistic versatility, meaning the platform grows smarter with each use—benefiting the entire community.
Together, these components create a flywheel effect: conversational access enables frictionless creation, ethical sourcing ensures long-term trust, and user feedback refines the model, leading to even more powerful creative tools. Soundverse isn’t just building AI for sound—it’s redefining how we collaborate with machines to make music and audio come alive.
8. Ethics and IP
![]()
Audio AGI raises thorny questions: Who owns the output? Does cloning Billie Holiday dilute her legacy? Can deepfake voices be weaponized?
Soundverse’s stance is clear:
-
Consent & Licensing First – No gray‑area scraping.
-
Transparent Attribution – Every generated stem carries provenance metadata.
-
Creator Choice – Opt‑out/opt‑in controls for style transfer and voice cloning.
-
Royalty– Future revenue splits flow back to rightsholders automatically.
Building trust is not a regulatory box‑check; it’s a competitive moat.
9. FAQ: Audio AGI and Soundverse
1. What is Audio AGI and how does it differ from other AI music tools?
Audio AGI refers to an audio‑first artificial general intelligence that can perceive, understand, create, and adapt sound with human‑level (or super‑human) fidelity and contextual awareness. Unlike single‑task audio tools (like stem splitters or simple text‑to‑music generators), Audio AGI combines real‑time responsiveness, deep genre knowledge, and conversational control to co‑compose, remix, and produce across all sonic domains.
2. How can I try out Soundverse’s Audio AGI features today?
You can experiment with core Audio AGI capabilities in Soundverse via:
-
AI Song Generator (full, conversational music creation): https://www.soundverse.ai/ai-song-generator
-
SAAR (voice-assisted music creation): https://www.soundverse.ai/saar-ai-music-assistant
-
Text‑to‑Music (quick instrumental demos): https://www.soundverse.ai/text-to-music
-
Stem Splitter & Vocal Remover (professional‑grade separation): https://www.soundverse.ai/stem-splitter-ai
3. Are AI‑generated tracks from Soundverse royalty-free?
Yes—Soundverse’s licensing tiers ensure your AI‑generated music is royalty‑free and cleared for commercial use under the appropriate plan. For full details on what you can do with each tier (Free, Creator, Pro, Enterprise) and how licensing works, see our Licensing Model FAQ:
https://help.soundverse.ai/faqs/licensing-model
4. How does Soundverse ensure its Audio AGI models are trained ethically?
Soundverse sources training data exclusively from licensed libraries, user submissions, and public‑domain recordings. Every generated stem carries embedded provenance metadata, and contributors can opt in or out of style‑transfer datasets. This “ethics by design” approach protects creator rights and fosters fair compensation.
5. Will Audio AGI replace human musicians and composers?
No. Soundverse’s vision is that Audio AGI amplifies human creativity rather than replacing it—much like DAWs empowered musicians rather than eliminated them. By handling routine composition and offering instant inspiration, Audio AGI frees creators to focus on emotional nuance, lyrics, performance, and storytelling—areas where human artistry remains irreplaceable.
10. Looking Forward
Headphones are becoming passthrough AR devices; cars are turning into rolling Dolby studios; gamers expect spatial audio by default. In this world, sound isn’t a layer—it’s the interface.
An Audio AGI won’t replace human ingenuity; it will amplify it, letting creators move from concept to immersive soundscape at the speed of imagination. And because music and speech are the universal languages, an ear‑first intelligence could prove the most human AI we build.
11. Join the Conversation
Soundverse is opening new beta waves every month. Whether you’re a bedroom producer, podcaster, indie filmmaker, or simply a curious listener, plug in, speak (or sing) your idea, and hear what an audio‑first AGI can do.
The next revolution won’t be televised—it’ll be heard.
Click below to start your free signup journey: